What is DeepCalpain
DeepCalpain is a web server based on deep learning to predict calpain-specific cleavage events. Given a protein or a set of proteins in FASTA format, it can predict the possible cleavage sites of two major types of calpain, including m-calpain and μ-calpain. DeepCalpain adopted four feature extraction methods to extract the sequence information and used a deep neural network to learn them, in the meanwhile, PSO (particle swarm optimizer) algorithm was used to fine turn the hyperparameters such as learning rate, layer numbers, activation functions and so on. DeepCalpain performed better than previous predictors for calpain-specific cleavage events.
About predicting performance
ROC for cross validation
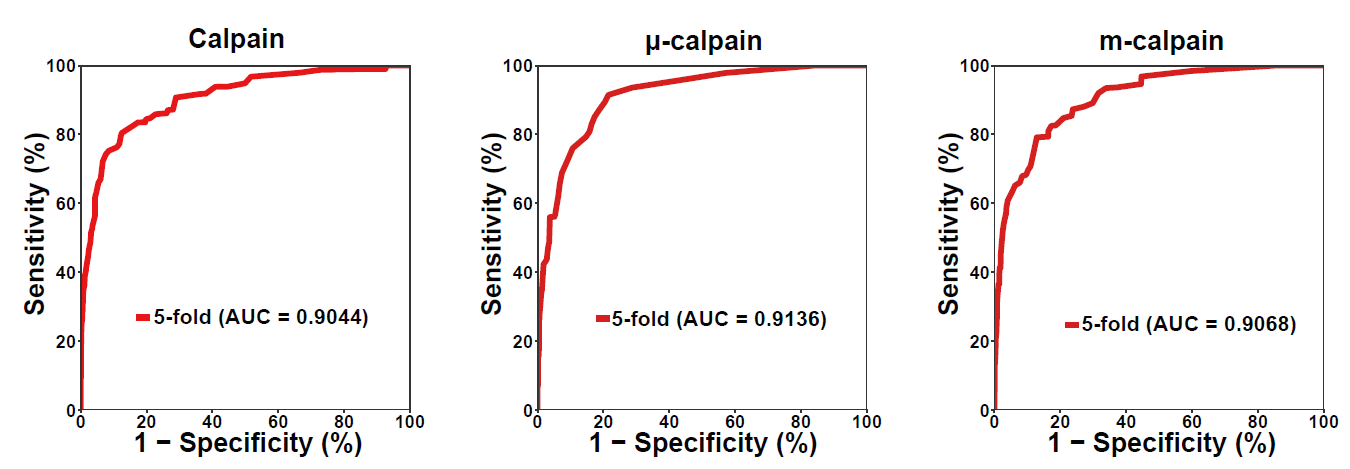
Cross validation performance
| Enzyme | Positive | Negative | Threshold | Specificity | Sensitivity | Precision |
|---|
| Enzyme | Positive | Negative | Threshold | Specificity | Sensitivity | Precision |
|---|---|---|---|---|---|---|
| calpain | 442 | 160698 | high | 0.9980 | 0.4140 | 0.3631 |
| medium | 0.9900 | 0.6742 | 0.1564 | |||
| low | 0.9500 | 0.8778 | 0.0461 | |||
| μ-calpain | 176 | 96640 | high | 0.9980 | 0.3977 | 0.2662 |
| medium | 0.9900 | 0.7216 | 0.1162 | |||
| low | 0.9500 | 0.8864 | 0.0313 | |||
| m-calpain | 256 | 63046 | high | 0.9980 | 0.3359 | 0.4076 |
| medium | 0.9900 | 0.6641 | 0.2125 | |||
| low | 0.9500 | 0.8867 | 0.0672 |
Usage procedures
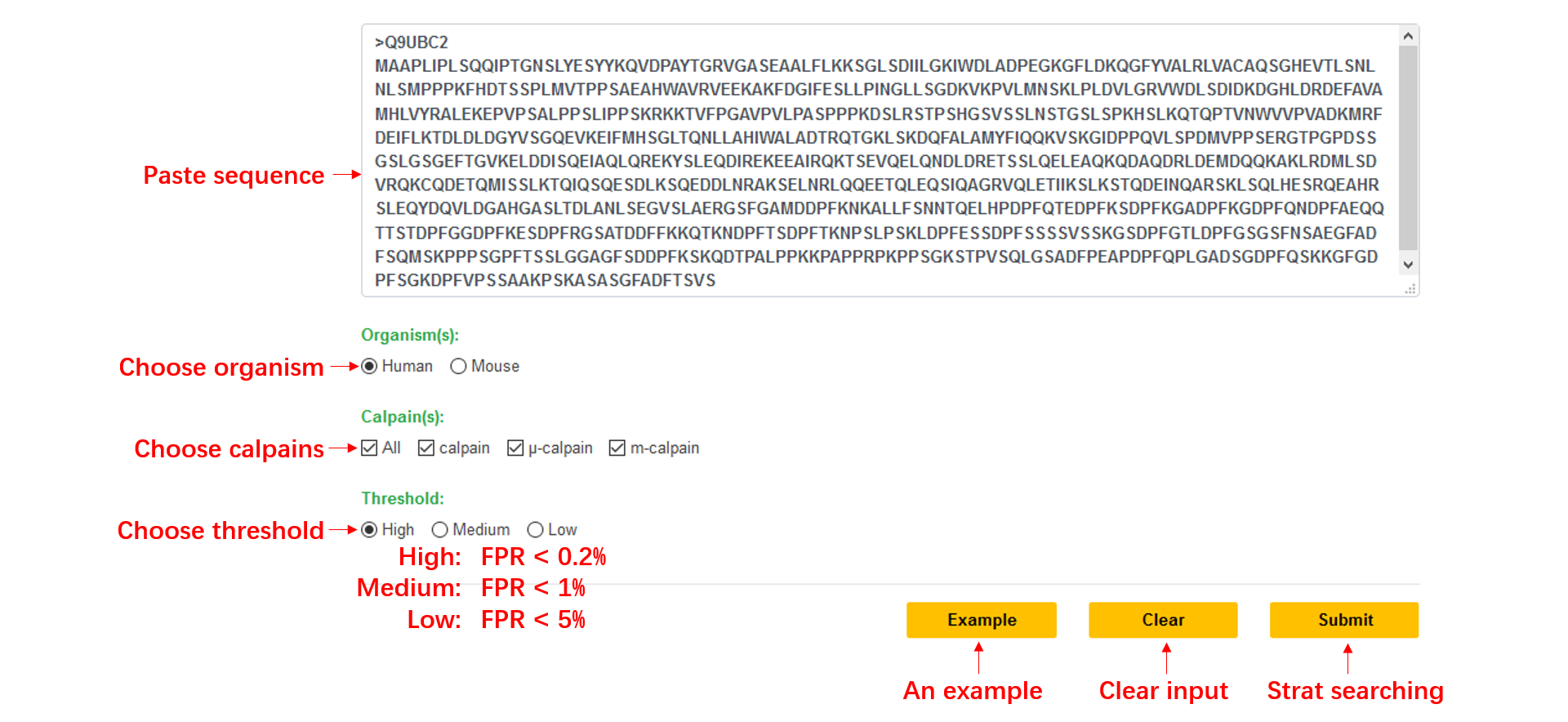
Step1: Paste your FASTA format sequence into the input textarea, or you can click the example button to run the default sequence.
Step2: Choose a kind of enzyme, if ‘All’ is selected, all enzymes will be predicted.
Step3: Choose a threshold to get a high confidence result, the default value is ‘Medium’.
Step4: Click Submit.
Output result explanation
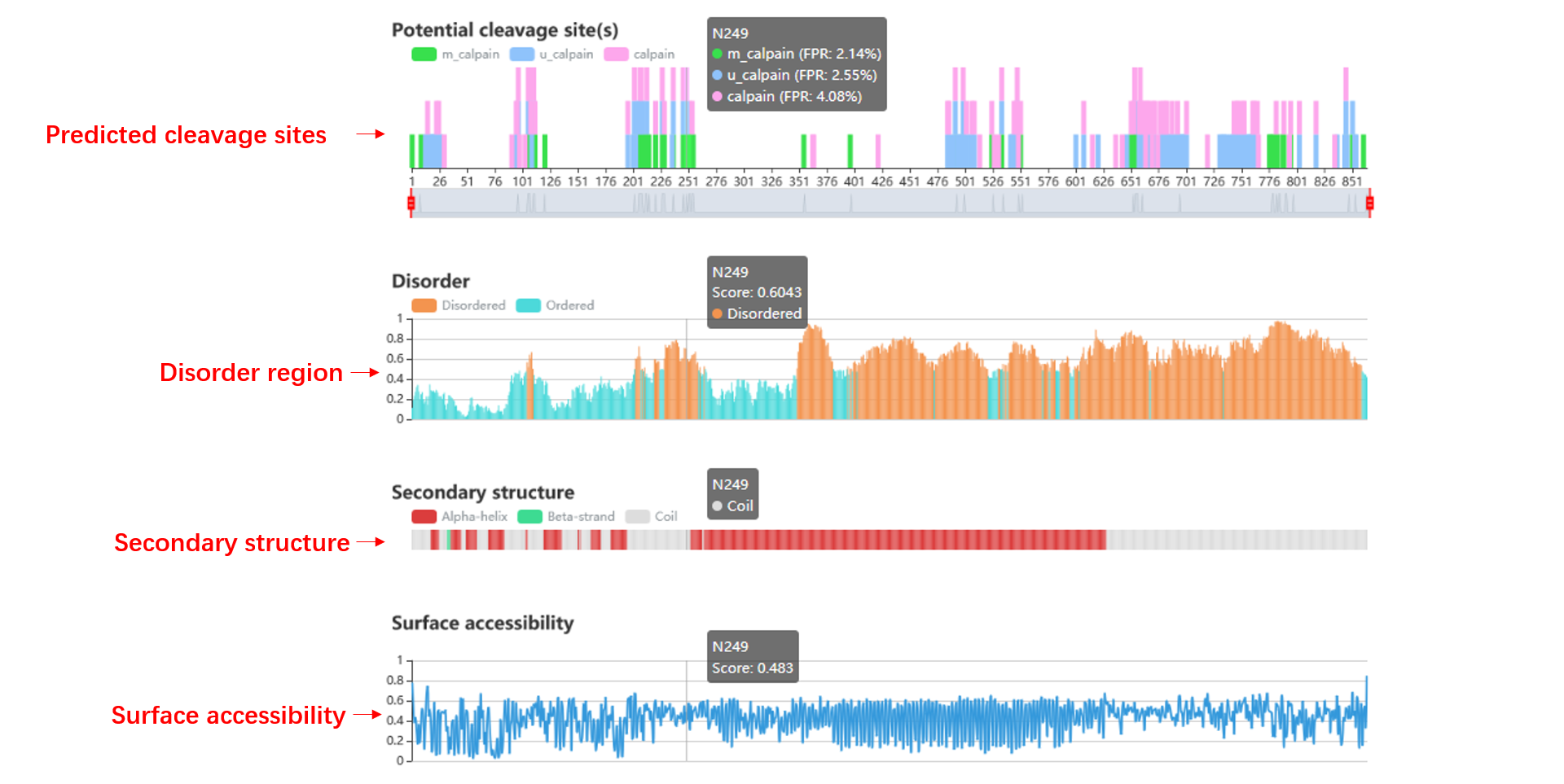
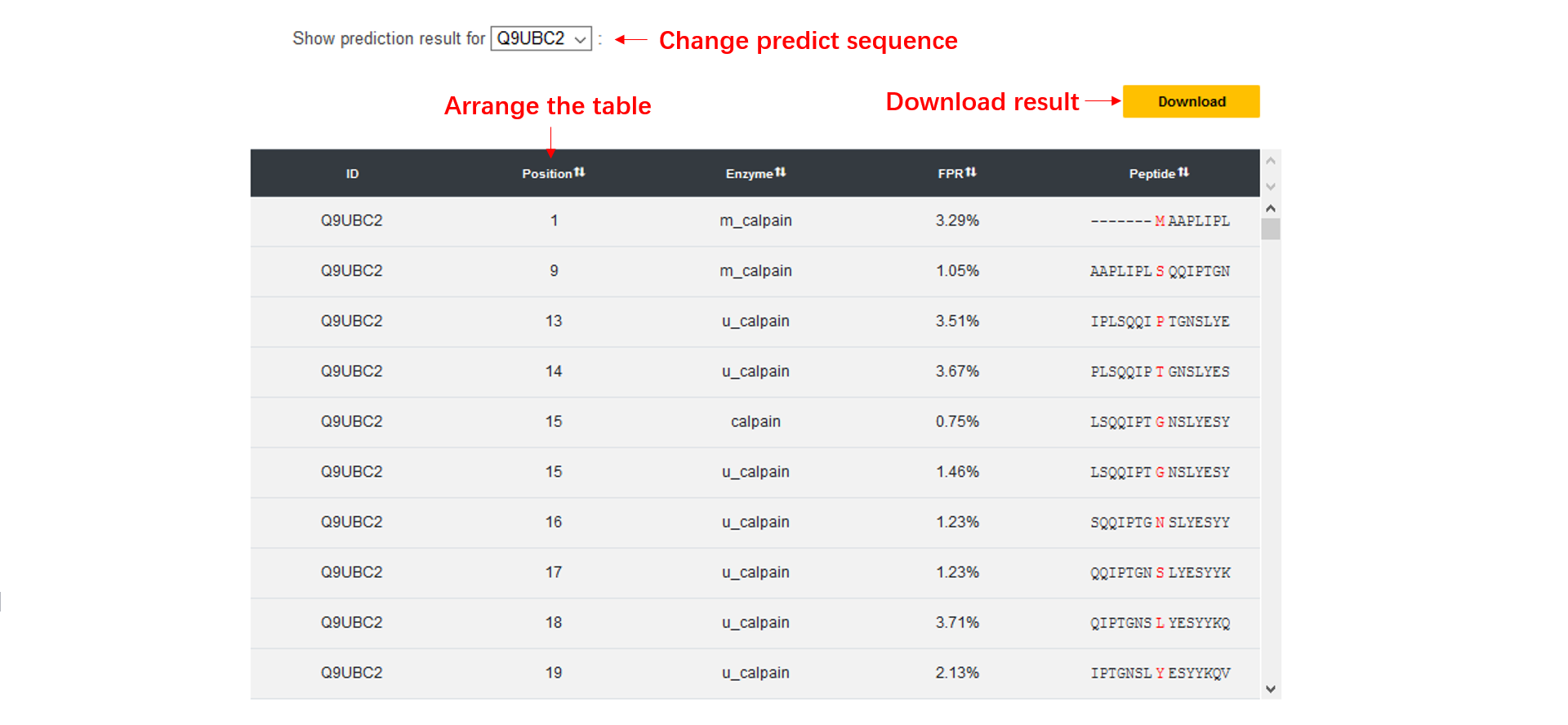
Potential calpain cleavage site(s)
This table contains five column, including FASTA title ID, position, calpain, FPR (false positive rate) and the peptide sequence window.
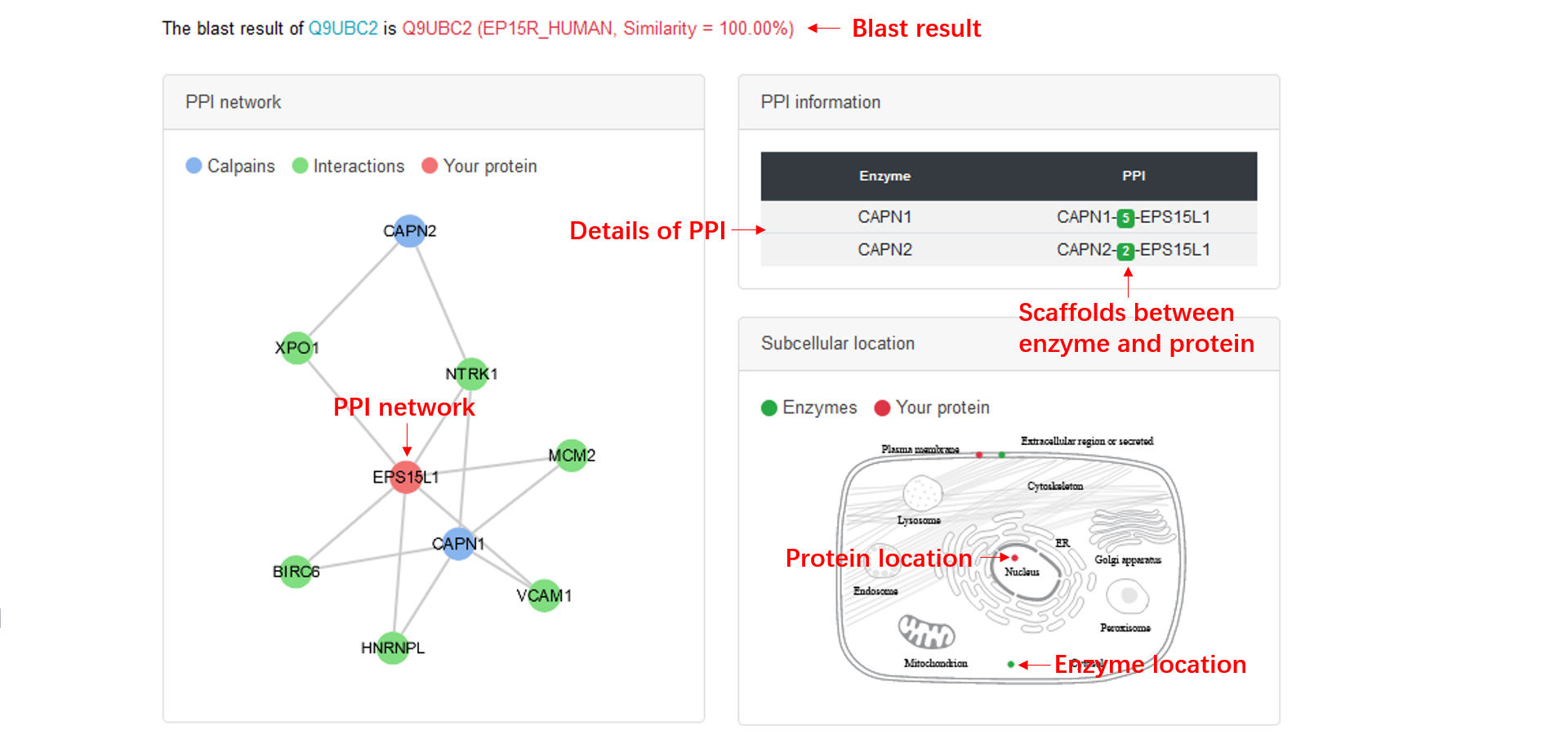
Network and colocalization
The PPI data are collected from several databases, the blue nodes are the calpains, the red node is the protein that matches query sequence best and green nodes are scaffolds.
Secondary structure and surface accessibility
The disorder values are calculated by IUPred. The surface accessibility and secondary structure information are predicted by NetSurfP. By the way, the predicted cleavage sites are labeled.